skelm.ELMClassifier¶
- class skelm.ELMClassifier(classes=None, alpha=1e-07, batch_size=None, include_original_features=False, n_neurons=None, ufunc='tanh', density=None, pairwise_metric=None, random_state=None)[source]¶
ELM classifier, modified for multi-label classification support.
- Parameters:
classes – Set of classes to consider in the model; can be expanded at runtime. Samples of other classes will have their output set to zero.
solver – Solver to use, “default” for build-in Least Squares or “ridge” for Ridge regression
Example descr…
- __init__(classes=None, alpha=1e-07, batch_size=None, include_original_features=False, n_neurons=None, ufunc='tanh', density=None, pairwise_metric=None, random_state=None)[source]¶
Scikit-ELM’s version of __init__, that only saves input parameters and does nothing else.
- fit(X, y=None) ELMClassifier[source]¶
Fit a classifier erasing any previously trained model.
- Returns:
self – Returns self.
- Return type:
- get_params(deep=True)¶
Get parameters for this estimator.
- partial_fit(X, y=None, forget=False, update_classes=False, compute_output_weights=True) ELMClassifier[source]¶
Update classifier with a new batch of data.
- Parameters:
X ({array-like, sparse matrix}, shape=[n_samples, n_features]) – Training input samples
y (array-like, shape=[n_samples, n_targets]) – Training targets
forget (boolean, default False) – |param_forget|
update_classes (boolean, default False) – Include new classes from y into the model, assuming they were 0 in all previous samples.
compute_output_weights (boolean, optional, default True) – |param_compute_output_weights|
- predict(X) _SupportsArray[dtype] | _NestedSequence[_SupportsArray[dtype]] | bool | int | float | complex | str | bytes | _NestedSequence[bool | int | float | complex | str | bytes][source]¶
Predict classes of new inputs X.
- Parameters:
X (array-like, shape (n_samples, n_features)) – The input samples.
- Returns:
y – Returns one most probable class for multi-class problem, or a binary vector of all relevant classes for multi-label problem.
- Return type:
ndarray, shape (n_samples,) or (n_samples, n_outputs)
- predict_proba(X) _SupportsArray[dtype] | _NestedSequence[_SupportsArray[dtype]] | bool | int | float | complex | str | bytes | _NestedSequence[bool | int | float | complex | str | bytes][source]¶
Probability estimation for all classes.
Positive class probabilities are computed as 1. / (1. + np.exp(-self.decision_function(X))); multiclass is handled by normalizing that over all classes.
- score(X, y, sample_weight=None)¶
Return the coefficient of determination of the prediction.
The coefficient of determination
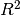 is defined as
is defined as
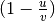 , where
, where 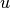 is the residual
sum of squares
is the residual
sum of squares ((y_true - y_pred)** 2).sum()and is the total sum of squares
is the total sum of squares ((y_true - y_true.mean()) ** 2).sum(). The best possible score is 1.0 and it can be negative (because the model can be arbitrarily worse). A constant model that always predicts the expected value of y, disregarding the input features, would get a score of 0.0.- Parameters:
X (array-like of shape (n_samples, n_features)) – Test samples. For some estimators this may be a precomputed kernel matrix or a list of generic objects instead with shape
(n_samples, n_samples_fitted), wheren_samples_fittedis the number of samples used in the fitting for the estimator.y (array-like of shape (n_samples,) or (n_samples, n_outputs)) – True values for X.
sample_weight (array-like of shape (n_samples,), default=None) – Sample weights.
- Returns:
score –
of self.predict(X)w.r.t. y.- Return type:
Notes
The
score used when calling scoreon a regressor usesmultioutput='uniform_average'from version 0.23 to keep consistent with default value ofr2_score(). This influences thescoremethod of all the multioutput regressors (except forMultiOutputRegressor).
- set_params(**params)¶
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
**params (dict) – Estimator parameters.
- Returns:
self – Estimator instance.
- Return type:
estimator instance