skelm.BatchCholeskySolver¶
- class skelm.BatchCholeskySolver(alpha: float = 1e-07)[source]¶
-
Methods
__init__([alpha])compute_output_weights()fit(X, y)Solves an L2-regularized linear system like Ridge regression, overwrites any previous solutions.
get_params([deep])Get parameters for this estimator.
partial_fit(X, y[, forget, ...])Update model with a new batch of data.
predict(X)score(X, y[, sample_weight])Return the coefficient of determination of the prediction.
set_params(**params)Set the parameters of this estimator.
Attributes
XtX_XtY_coef_intercept_- fit(X, y)[source]¶
Solves an L2-regularized linear system like Ridge regression, overwrites any previous solutions.
- get_params(deep=True)¶
Get parameters for this estimator.
- partial_fit(X, y, forget=False, compute_output_weights=True) BatchCholeskySolver[source]¶
Update model with a new batch of data.
Output weight computation can be temporary turned off for faster processing. This will mark model as not fit. Enable compute_output_weights in the final call to partial_fit.
- Parameters:
X ({array-like, sparse matrix}, shape=[n_samples, n_features]) – Training input samples
y (array-like, shape=[n_samples, n_targets]) – Training targets
forget (boolean, default False) – Performs a negative update, effectively removing the information given by training samples from the model. Output weights need to be re-computed after forgetting data.
compute_output_weights (boolean, optional, default True) –
Whether to compute new output weights (coef_, intercept_). Disable this in intermediate partial_fit steps to run computations faster, then enable in the last call to compute the new solution.
Note
Solution can be updated without extra data by setting X=None and y=None.
- score(X, y, sample_weight=None)¶
Return the coefficient of determination of the prediction.
The coefficient of determination
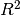 is defined as
is defined as
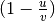 , where
, where 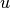 is the residual
sum of squares
is the residual
sum of squares ((y_true - y_pred)** 2).sum()and is the total sum of squares
is the total sum of squares ((y_true - y_true.mean()) ** 2).sum(). The best possible score is 1.0 and it can be negative (because the model can be arbitrarily worse). A constant model that always predicts the expected value of y, disregarding the input features, would get a score of 0.0.- Parameters:
X (array-like of shape (n_samples, n_features)) – Test samples. For some estimators this may be a precomputed kernel matrix or a list of generic objects instead with shape
(n_samples, n_samples_fitted), wheren_samples_fittedis the number of samples used in the fitting for the estimator.y (array-like of shape (n_samples,) or (n_samples, n_outputs)) – True values for X.
sample_weight (array-like of shape (n_samples,), default=None) – Sample weights.
- Returns:
score –
of self.predict(X)w.r.t. y.- Return type:
Notes
The
score used when calling scoreon a regressor usesmultioutput='uniform_average'from version 0.23 to keep consistent with default value ofr2_score(). This influences thescoremethod of all the multioutput regressors (except forMultiOutputRegressor).
- set_params(**params)¶
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
**params (dict) – Estimator parameters.
- Returns:
self – Estimator instance.
- Return type:
estimator instance